Chapter 4 Missing values
We start by graphing the missing values by variable.Missing Values by Variable
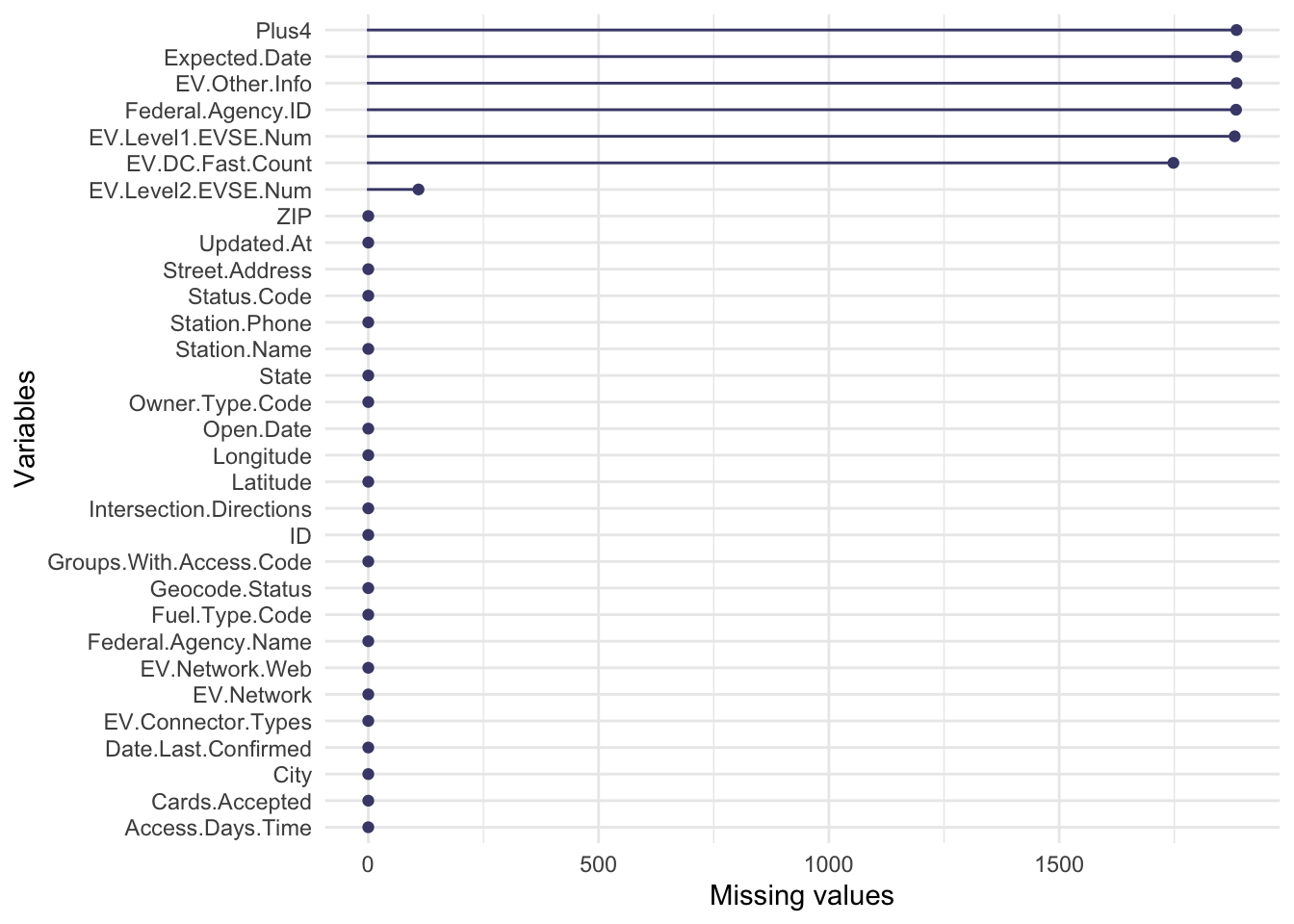
Graph missing values by variable, facet on the month of information updating time
The graph only plots variables that have a large proportion of missing values.
Given the proportion of data by information updating month, the number of missing values is proportional to the total number of entries for each month.
## # A tibble: 11 x 2
## Updated.month Prop
## <dbl> <dbl>
## 1 2 0.00106
## 2 3 0.0313
## 3 4 0.0743
## 4 5 0.00690
## 5 6 0.0647
## 6 7 0.00212
## 7 8 0.0276
## 8 9 0.0297
## 9 10 0.0133
## 10 11 0.263
## 11 12 0.486We conclude that there is no pattern for the input of missing values.
However, since some of the missing values are not captured in the above graph, we also try using the visna graph to plot the missing values by variable, and sort by variable with the most to least missing values.
## NOTE: In the following pairs of variables, the missingness pattern of the second is a subset of the first.
## Please verify whether they are in fact logically distinct variables.
## [,1] [,2]
## [1,] "Intersection.Directions" "Access.Days.Time"
## [2,] "Plus4" "Station.Phone"
## [3,] "Plus4" "Access.Days.Time"
## [4,] "Plus4" "Cards.Accepted"
## [5,] "Plus4" "EV.Level1.EVSE.Num"
## [6,] "Plus4" "EV.Level2.EVSE.Num"
## [7,] "Plus4" "EV.DC.Fast.Count"
## [8,] "Plus4" "EV.Network.Web"
## [9,] "Plus4" "Owner.Type.Code"
## [10,] "Plus4" "Federal.Agency.ID"
## [11,] "Plus4" "Federal.Agency.Name"
## [12,] "Plus4" "Open.Date"
## [13,] "Expected.Date" "Access.Days.Time"
## [14,] "Expected.Date" "Cards.Accepted"
## [15,] "Expected.Date" "EV.Level1.EVSE.Num"
## [16,] "Expected.Date" "EV.Level2.EVSE.Num"
## [17,] "Expected.Date" "EV.DC.Fast.Count"
## [18,] "Expected.Date" "EV.Network.Web"
## [19,] "Expected.Date" "Owner.Type.Code"
## [20,] "Expected.Date" "Federal.Agency.ID"
## [21,] "Expected.Date" "Federal.Agency.Name"
## [22,] "Expected.Date" "Open.Date"
## [23,] "Cards.Accepted" "Owner.Type.Code"
## [24,] "Cards.Accepted" "Open.Date"
## [25,] "EV.Level1.EVSE.Num" "Owner.Type.Code"
## [26,] "EV.Level1.EVSE.Num" "Open.Date"
## [27,] "EV.Other.Info" "EV.Network.Web"
## [28,] "EV.Other.Info" "Owner.Type.Code"
## [29,] "EV.Other.Info" "Federal.Agency.ID"
## [30,] "EV.Other.Info" "Federal.Agency.Name"
## [31,] "EV.Other.Info" "Open.Date"
## [32,] "Owner.Type.Code" "Open.Date"
## [33,] "Federal.Agency.ID" "Open.Date"
## [34,] "Federal.Agency.Name" "Open.Date" TRUE
TRUE
From the graph, it does not seem to have obvious patterns in the missing values. So we directly drop the columns that contains only NA values, such as Plus4 and Expected Date.